
点点
2024-04-16 21:35 阅读 239 喜欢 0
用于对微信聊天记录进行可视化。
下面这些图片都可以自动生成:

相信大部分小伙伴们的聊天记录都在手机里面,电脑的聊天记录不全。所以先把手机的聊天记录同步到电脑上,这个小伙伴们在换手机的时候可能有过体验:微信 - 设置 - 聊天 - 聊天记录迁移与备份 - 迁移。等个几分钟吧,等待时间取决于您的聊天记录量有多大。
解密2:输入个人信息,获取信息。然后解密:开始启动!
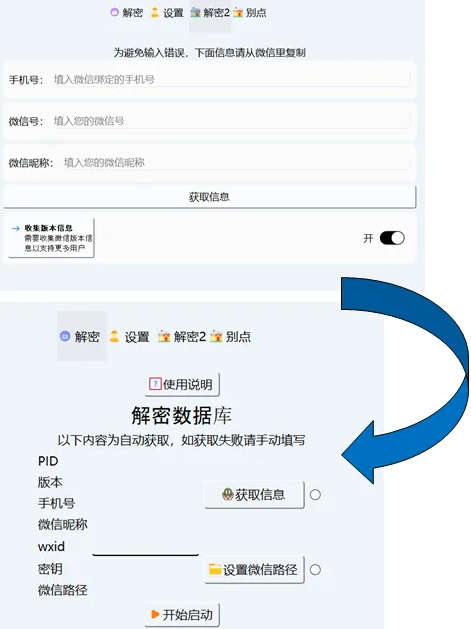
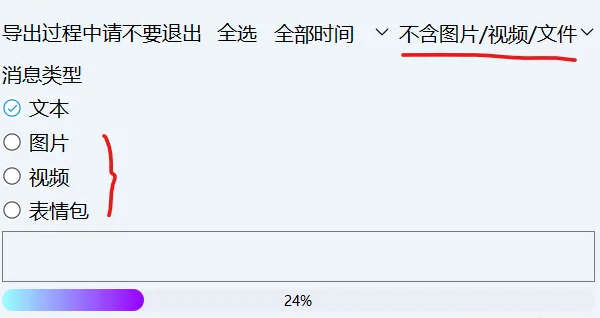
然后就可以在好友中导出聊天记录了。为了减少乱码,请勿勾选图片、视频、表情包,导出的不含图片/视频/文件!
导出完毕,退出软件。在软件同一目录下会出现一个 data目录,点进去,data/聊天记录/ 下面会有个 csv 文件。大概长这个样子:

把这个csv文件拷贝到 WechatVisualization 的 input_data/ 目录里面。
使用者需要具备基本的 Python 知识(如何运行代码),电脑上已经安装了 Anaconda 或者 Python(版本>=3.7)。如果用 Anaconda,最好新建一个环境。
依次安装必要的第三方库:
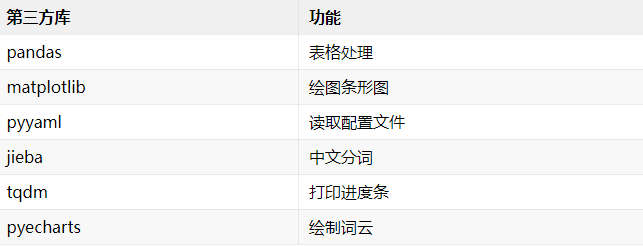
安装方法不是本篇重点,基本上都是 pip install ,如果遇到问题请自行上网搜索解决方法,在此不赘。
配置文件为 config.yml,用记事本就可以打开了,当然用代码编辑器更好,因为可以语法高亮。
里面可以自行设置的内容有
# 输入数据
# 下面这些文件都放在input_data目录下
# 聊天记录
msg_file: msg.csv
# 微信表情中英文对照表
emoji_file: emoji.txt
# 停用词表,一般是没有实际意义的词,不想让被分析到的词都放在这里
stopword_file: stopwords_hit_modified.txt
# 词语转换表,用于合并意义相近的词,比如把“看到”、“看见”、“看看”都转换为“看”
transform_file: transformDict.txt
# 用户自定义词典,用于添加大部分字典没有的、但自己觉得不能分开的词,如i人、e人、腾讯会议
user_dict_file: userDict.txt
# 名字
# name1是自己的名字
name1: person 1
# name2是对方的名字
name2: person 2
# name_both是双方共同的名字
name_both: both
# 局部参数
# top_k是绘制前多少个词
# 如果词或表情的出现频次低于word_min_count或emoji_min_count,就不会被分析
# figsize是绘图图窗尺寸,第一个是宽度,第二个是高度
word_specificity:
top_k: 25
word_min_count: 2
figsize:
- 10
- 12
emoji_specificity:
emoji_min_count: 1
top_k: 5
figsize:
- 10
- 12
word_commonality:
top_k: 25
figsize:
- 10
- 12
emoji_commonality:
top_k: 5
figsize:
- 12
- 12
time_analysis:
figsize:
- 12
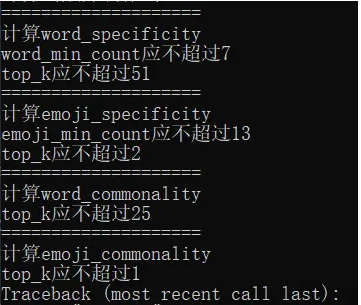
- 8可以在代码编辑器中直接运行 main.py,也可以在命令行中(先激活之前创建的环境)运行 python main.py。
成功运行应显示如下信息:
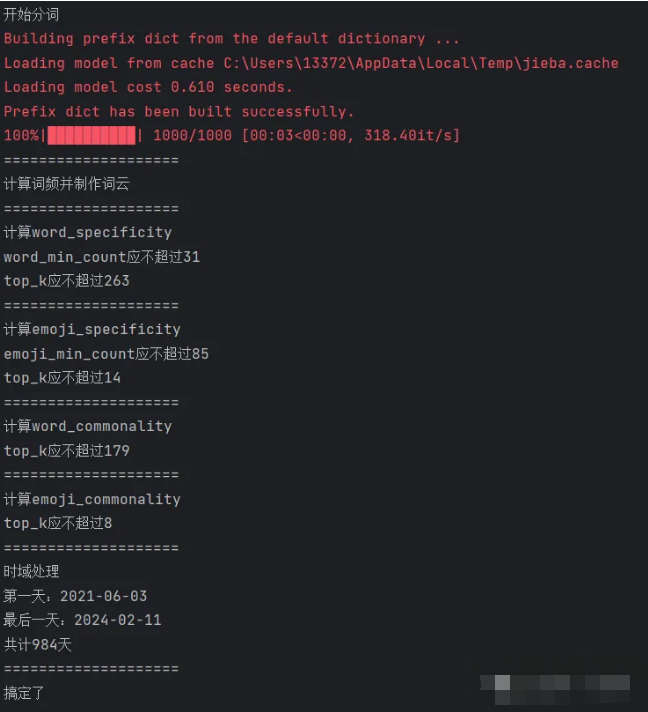
生成的图片可以在当前目录的 figs 文件夹中找到。
查看生成的图片,可能会有些词不是自己想要的,抑或有些自己想要的词被拆分了,此时到 input_data/ 目录下面修改各文件即可。这是一个不断迭代的过程,也就是数据清洗,比较耗时间。但没办法,如果想要质量比较高的结果,就耐心好好做一下,把数据清洗干净。
emoji.txt 是微信表情的中英文对照。微信表情在聊天记录中是以[捂脸]或者[Facepalm]的形式呈现的。我的聊天记录里面中英文的[xxx]都有,所以建立一个对照表,把所有的英文都替换成中文。如果您发现有的表情文字还是英文,可以在里面添加其中文,以便合并。 stopwords_hit_modified.txt 是停用词表。诸如“现在”、“进行”、“好像”这种(我自认为)没有实际意义的词,不应该被统计,直接把它们剔除。如果你觉得生成的结果里面有你不想看到的词,可以在这里添加。 transformDict.txt 把一些词转换成另一些词。诸如“看到”、“看见”、“看”、“看看”这些同义词可能被分别统计,完全没必要,我们可以把它们合并为一个词“看”。为此,只需在两栏中分别填写原词与转换词即可。注意,两栏用的是制表符(Tab)隔开。 usreDict 可以添加传统词典中没有的词,比如 “e人”、“i人”、“腾讯会议”等。如果不自行添加这些词,后果是它们可能会被拆成“e”、“i”、“人”、“腾讯”、“会议”这些词,这不是我们希望看到的。
ValueError: shape mismatch: objects cannot be broadcast to a single shape
ValueError: The number of FixedLocator locations (5), usually from a call to set_ticks, does not match the number of ticklabels (1).
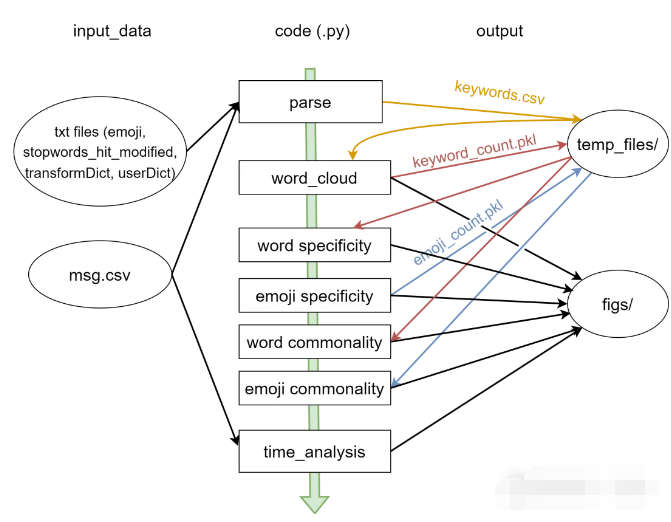
parse.py 读取 input_data/ 中的文件,执行分词。生成 keywords.csv 放入 temp_files/ ,里面在原数据基础上新增两列,一列是被拆分的词,一列是提取出的微信表情。
word_cloud.py 计算词频,生成 pickle 文件 keyword_count.pkl 放入 temp_files/ ,同时制作词云放入 figs/。
利用上一步计算的词频,计算词语专属性。图片放入 figs/。
计算微信表情出现频次,生成 pickle 文件 emoji_count.pkl 放入 temp_files/ 同时计算表情专属性。图片放入 figs/。
利用词频,计算词语共有性。图片放入 figs/。
利用表情频次,计算表情共有性。图片放入 figs/。
利用微信聊天记录原始文件,进行时间信息分析。图片放入 figs/。
记自己发送过某个词 的次数为 ,对方发送过某个词 的次数为 。
专属性表明自己常说,对方不常说(反之亦然)。我对专属性的考虑是这样的,假如有三个词 A、B、C。
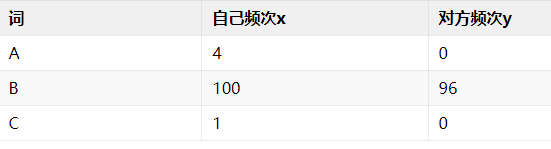
对于自己来说,显然A的专属性应该是最高的。B词的话,两个人虽然也是差了4次,但是基数比较大,差了4次其实无明显对比。C的话,基数太小,要说C是自己专属的词汇,可靠性不高。
共用性表明两个人都常说某个词。所以首先排除那些有一方从来没说过的词。为此,首先对双方说过的词取交集。
现在我们还是假设有三个词 A、B、C。
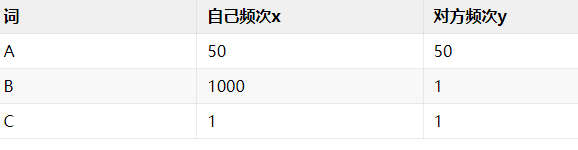
B词被自己说过的次数比对方多得多,共有性显然很低。C词虽然双方说过的次数差不多,但基数太小,不能得出可靠结论。所以A词共有性最高。那怎么算呢?
共有性是专属性的反面,那我们能不能用专属性的倒数呢?我觉得不好,一方面因为分母是 ,容易出现零值;另一方面对于A词(50,50)和C词(1,1)不能做很好地区分。
为此,我使用了调和平均值:
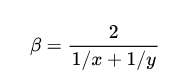
为什么这里使用调和平均值而不使用其他平均值呢,因为调和平均值是四大平均值中最偏向较小数的那个,“共有性”就是强调两个人都要经常说,不能光一个人说另一个人不说,也即一方说得再多,对于共有性的影响也很小,比如B词(1000,1)。
用调和平均值可以确保A词具有最大的共有性。
以上就是微信聊天记录可视化工具的介绍,喜欢文章,关注小编,后期会有更多的科技资讯。
转载请注明出处: http://sdxlp.cn/article/tureoigujfdjng.html


