
点点
2021-03-29 09:04 阅读 586 喜欢 0
例如我们定义一个字体<1> 但是对应的svg显示为<5> ,那么肉眼看到的是5 ,通过源码或抓取得到的确是1。 之前的时候是通过一个字体文件,现在慢慢演变为动态字体,每次看到的都不同,所以现在我们需要对字体进行解析,得到最终的数据。
http://glidedsky.com/level/crawler-font-puzzle-1 ,关于字体反爬的一个课题。
根据给予的地址,可以看到不同的源码与数字,那么我们可以通过控制台找到这种字体,通过页面中的base64来指定的字体文件。
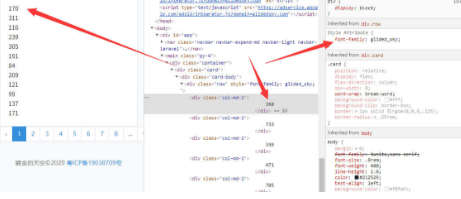 先将base64 转为 ttf 文件
先将base64 转为 ttf 文件
代码或工具都可以: https://www.motobit.com/util/base64-decoder-encoder.asp 工具转换。
const base64str = xxxx由于太长,此处不写了;//data:font;charset=utf-8;base64, 之后的内容,不要逗号
const fs = require('fs');
fs.writeFileSync('./demo.ttf',Buffer.from(base64str,'base64'));
通过fontcreator软件打开后可以看到,字体展示与unicode标注的都是不同的。
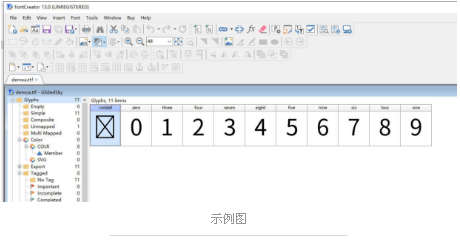
现在,我还没找到除了ocr识别外的更好的办法,之前看文档有说可以从ttf中拿到映射关系的,不过没处理出来..能力有限。而且,这个我也没有使用ocr,直接使用了一个下标判断。
将ttf解析为xml ,并转为对象,然后获取下标,得到映射
const font = require('font-carrier'); const xml2json = require('xml2json');
//加载字体
let transFont = font.transfer('./demo.ttf');
let str = transFont.toString();
let json = xml2json.toJson(str);
let obj = JSON.parse(json);
let fonts = obj.svg.defs.font.glyph;
let map = {};
//就目前来看,还没找到对应的映射关系,比较理想的是,根据下标,除去第一个,从0开始。
fonts.forEach((t, i) => {
if (i>0) {
let code = t.unicode;//4
let index = i - 1;//0
//对应的意思就是:给浏览器一个字符串4 ,显示出来是 0 。
map[code] = index;
}
})
console.log(map);
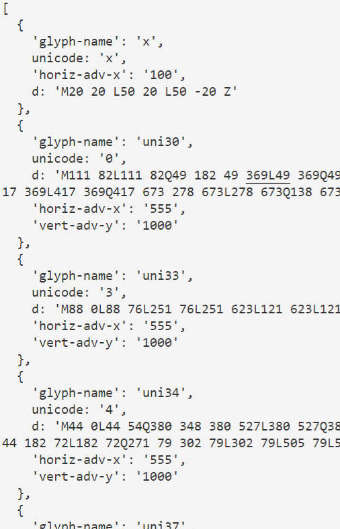 剩下的就是一页一页的抓取,然后获取ttf并解析,最终进行匹配了..
剩下的就是一页一页的抓取,然后获取ttf并解析,最终进行匹配了..
转载请注明出处: http://sdxlp.cn/article/zitifanpa.html


